Informace jako na dlani |
 |
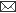 |
| Sobota, 18. duben 2015 |
|
Hodně informací, málo časuk
Stále větší množství informací vyžaduje ale i stále více času k vyhledání požadovaných údajů. Času na procházení nekonečných sérií digitalizovaných dokumentů se však dostává málokomu, a proto na řadu přicházejí nezbytné nástroje, které umožňují efektivní a přesné vyhledávání požadovaných informací v milionech naskenovaných stránek. Tvorbou takovýchto řešení se zabývají i vývojáři společnosti Siemens, kteří představili program umožňující bleskové vyhledávání v rozsáhlých digitalizovaných souborech, aniž by bylo nutné jejich otevření.
Tisíce stran nejsou překážkou Program byl původně určen pro snazší orientaci právě v datech z katastrů nemovitostí. Protože se jedná až o několik desítek let staré dokumenty, psané zpravidla na psacích strojích, v nichž bývají často dopisovány ještě různé úpravy, vyžadoval program značně robustní algoritmy, které jsou schopny i za takto nepřívětivých podmínek správně identifikovat vyhledávána hesla. Vývojáři následně program upravili, aby mohl sloužit ke snazší orientaci i v jiných typech textových materiálů, jako je například dokumentace k výběrovým řízením.
Tyto typy dokumentů mívají často přes tisíc stránek a mohou navíc obsahovat stejný druh informací i vícekrát v závislosti na tom, jak se dodatečně upravovalo zadání projektu. Vyhledávání proto funguje tak, že automaticky zobrazuje i změny, ke kterým v souvislosti s hledaným tématem došlo ve starších verzích dokumentu.
Sémantika, základ inteligentního hledání Cílem vývojářů je naučit software základům sémantiky a umožnit mu automatické vyhledávání příbuzných témat ve starších dokumentech. Uživatel by tak měl prakticky ihned k dispozici veškeré důležité i potenciálně zajímavé informace s podobnou tématikou bez časově náročné rešerše. V budoucnu by se pak podobné programy využívající znalosti sémantiky mohly rozšířit i do dalších sfér, jako je třeba právo či medicína. Vyhledávání judikatur nebo diagnóz vzácných onemocnění by pak bylo doslova otázkou jen pár minut.
Informace jako na dlani _01.jpg: Převést miliony stran dokumentů do digitální podoby není až tak komplikované, jak by se mohlo zdát – automatické skenery jsou schopné naskenovat až 2000 stran za hodinu. Orientace a následné vyhledávání v milionech elektronických stránek je podstatně větší výzvou, vyžadující pokročilé algoritmy pro analýzu obrazu. Informace jako na dlani_02.jpg: Práce s dokumenty v digitální podobě dokáže oproti ručnímu procházení stohů papíru ušetřit spoustu času, podmínkou jsou však propracované systémy pro vyhledávání.
|
 V dnešní době jsou nejcennějším a nejméně dostatkovým zbožím dvě komodity – informace a čas. Přitom díky digitalizaci a zejména mocnému internetu máme přístup doslova k neuvěřitelnému množství dat. Jen na servery YouTube přibude každou hodinu v průměru 100 hodin videa a Google se musí každou vteřinu vypořádat s více než 40 000 vyhledávacími dotazy. Navzdory snadné dostupnosti informací (nebo možná právě kvůli ní) žízeň lidstva po dalších stále roste. Do digitální formy se proto předělávají i historické dokumenty – včetně středověkých archiválií či záznamů z katastru nemovitostí – zahrnující desítky let staré materiály.
V dnešní době jsou nejcennějším a nejméně dostatkovým zbožím dvě komodity – informace a čas. Přitom díky digitalizaci a zejména mocnému internetu máme přístup doslova k neuvěřitelnému množství dat. Jen na servery YouTube přibude každou hodinu v průměru 100 hodin videa a Google se musí každou vteřinu vypořádat s více než 40 000 vyhledávacími dotazy. Navzdory snadné dostupnosti informací (nebo možná právě kvůli ní) žízeň lidstva po dalších stále roste. Do digitální formy se proto předělávají i historické dokumenty – včetně středověkých archiválií či záznamů z katastru nemovitostí – zahrnující desítky let staré materiály. Obrázky - popisek:
Obrázky - popisek: Články na podobné téma
Přehled nových článků



Naše další portály:
![]()
- „Internet věcí“ pro techniky údržby aneb Proč sdílet data z měřicích přístrojů?
- Fluke Specials jsou branou pro pravidelné výhodnější nabídky
![]()
- Prestižní RedDot za barvy a design
- Čtečky čárových kódů – žádné kompromisy, když přijde na modularitu
- LED s vyzařovacím úhlem až 270°
![]()
- Panasonic nabízí svět virtuální reality
- Jednoduchá komunikace mezi řídící jednotkou a inteligentním senzorem
![]()